















DeepSeek横空出世,各行各业都在热火朝天地测试它的能力上限,自主选拔在线团队自然也不能免俗,想看一下号称目前地表最强之一的人工智能,和智商巅峰期的人类——高三考生,究竟谁能更胜一筹!
自主选拔在线团队打算用一套北大强基计划试题,来测试一下DeepSeek在数学直觉、逻辑推理、计算方面的水平,看它是否能达到“经过系统性学习和训练”的高三学生水平!
温馨提示:为方便大家交流联系,欢迎大家扫描下方二维码加入"2025强基综合评价交流群",我们有专业的老师将为大家线上答疑。
扫一扫即可进群
如果加群失败,可在企业微信联系人中 添加青桐老师(微信号:15321584635)好友,备注:省市-高考年份。

测试说明
1.本次参与测试的AI为DeepSeek R1 深度思考模式;
2.测试题目为2021年北京大学强基计划数学试题,全卷共20题,每题5分;
3.原测试为选择题,为避免“蒙”答案的可能性,我们改为填空题形式;
4.测试时长为60分钟(与真实考试相同),包括思考及答题时间,超时作答不计分。
作答情况
因DeepSeek作答步骤太长,故仅展示前五道题的具体解答步骤,正确率和总时长可移步下一部分总结分析:
第一题:结果正确,输出证明错误。

第二题:结果错误。

第三题:结果正确。

第四题:题目读错了,算错了结果。
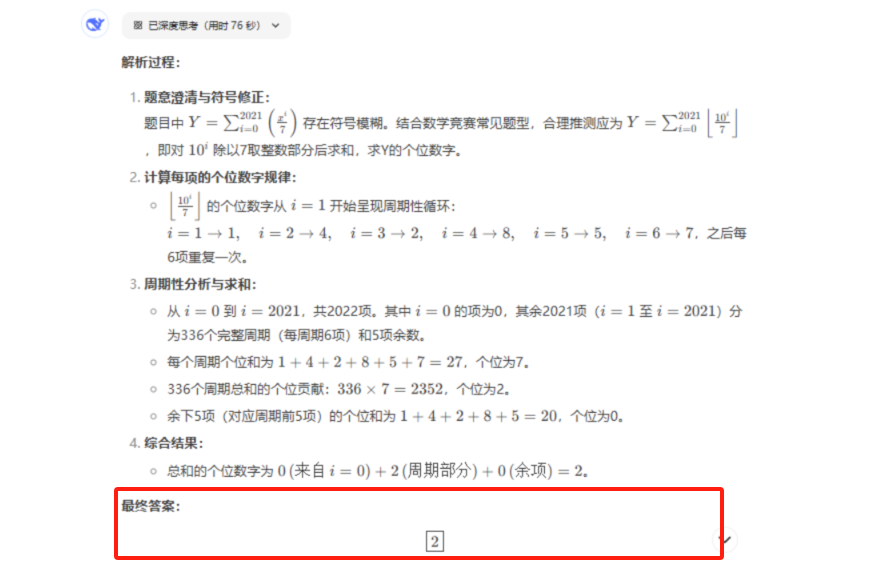
第五题:题干理解错误,导致结果错误。

总结评价
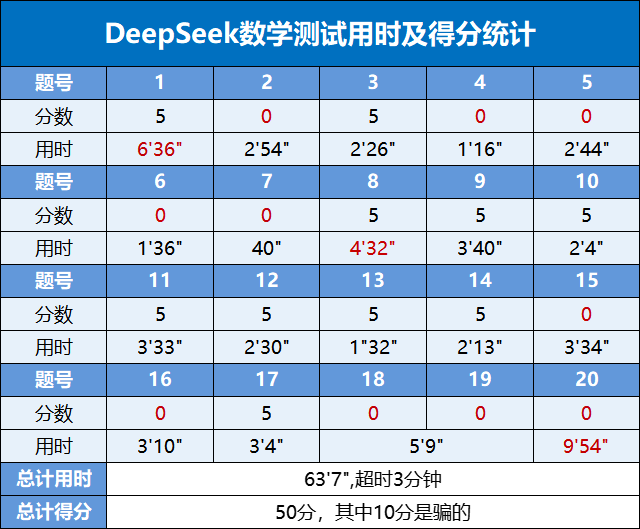
这套卷子是北京大学2021年强基计划的数学真题(回忆版),为了防止DeepSeek乱蒙,因此以填空的形式给DeepSeek做,相当于给DeepSeek增加了一些难度。
在考试时候,这套卷子的要求用时是一个小时,对于人类来说是比较紧张的,可以看出对于DeepSeek也很紧张,最后加起来整体上超时了3分多钟,不过其实直到最后一题之前,DeepSeek对时间的控制和规划都还是不错的,所以这个超时是完全超在了最后一题不会做上了。
最终的得分是50分,这个分数大概正好在面试线上下,所以DeepSeek本次所展现出的实力大概是强基计划刚好压线的水平。做对的10道题中有2道是蒙对的,这也合理,人类做这些题蒙个一两道也是常见的。
从做对的题目的分布来看,DeepSeek的强项是有明确成熟模型的计算题,或者逻辑不太复杂、规模也不太大,靠计算能力可以硬算的题目。而做错的题主要分两类,一类是逻辑上理不顺的题目,另一类是看不懂的题目。
其实从思考过程中可以看出,即便是没做对的题,有很多其实一开始DeepSeek也找到了正确的思路,但是没有坚持下去,或者后续的变形略微复杂,超出了他的理解能力。而在面对不太常见的复杂表达的式子时,DeepSeek几乎全都读错了题,而在读错题的时候,他能够意识到读错了,并会把大部分时间用于猜测真正的题目是什么,不过成功率并不高。
DeepSeek做题的另一个特点是自我怀疑和陷入幻觉的情况较多,无论做对或是做错,都会反复问自己做得对不对,一般都要至少检查三遍才敢确认结果。
总体来说,如果按照拟人的形式来给DeepSeek做一个画像的话,这次测试中,DeepSeek所展现的形象比较类似于一个兴趣广泛,提前学习了一些超纲知识,对自己的计算能力很自信但是又不太有耐心,不喜欢复杂逻辑推理,又有点强迫症的学生。
整个分析看下来,我们可以发现DeepSeek的一些弱点在考生们的身上时不时也会有所体现。考生可能没有人工智能那么强大的计算能力,但是在思维上我们可以更轻松地理解各种复杂的逻辑概念,经过训练我们可以更容易地产生解决问题的巧思。这种具有逻辑性和创造性的思维,正是强基计划对人才的要求,也是同学们未来代表人类去探索知识边界必备的素质。
祝读到这里的各位考生们,未来都能昂首挺胸,骄傲地说道:”AI不会取代我,而只会成为我手中新的利刃“。


















px.png)
